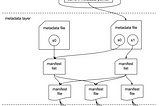
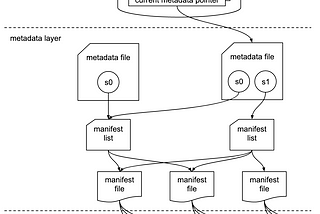
PinnedInternals of Apache IcebergIn this blog we are going to explore the architectural components of the Apache Iceberg.Jul 2, 2023Jul 2, 2023
How to create StructType schema from JSON schema | PySparkUsing Apache Spark class pyspark.sql.types.StructType method fromJson we can create StructType schema using a defined JSON schema.Nov 25, 2024Nov 25, 2024
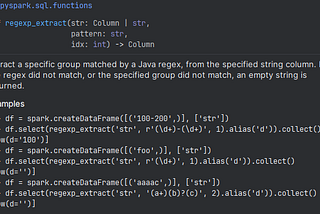
PySpark — Log Parsing using regexp_extractApache Spark built-in function regexp_extract that takes input as an column object, regex expression as string and group index & extract a…May 28, 2024May 28, 2024
Polars Dataframe — SQL InterfaceWhile dealing with polars dataframes in Python, instead of using dataframes APIs (eg. fiter, select, join etc.) for data transformation…Apr 15, 20241Apr 15, 20241
Apache Iceberg — Hidden PartitioningIn this blog we will explore “Hidden Partitioning” concept in Apache Iceberg.Mar 30, 2024Mar 30, 2024
MinIO — High Performance Object StorageMinIO is a high-performance, kubernetes native object storage.Aug 20, 2023Aug 20, 2023
Apache Spark — Log Parsing using regexp_extractApache Spark built-in function regexp_extract that takes input as an column object, regex expression as string and group index & extract a…Aug 19, 2023Aug 19, 2023
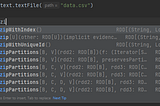
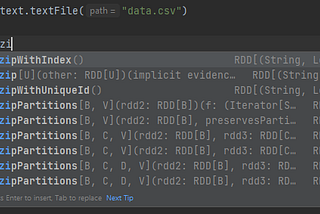
Spark Scala — RDD zipWithIndexSuppose you have a file with unwanted lines in its header, which you don’t wanted to process.Aug 17, 2023Aug 17, 2023
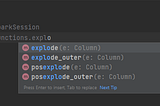
Apache Spark: Explode FunctionApache Spark built-in function that takes input as an column object (array or map type) and returns a new row for each element in the given…Aug 15, 2023Aug 15, 2023
Apache Iceberg — Insert OverwriteINSERT OVERWRITE can replace/overwrite the data in iceberg table, depending on configurations set and how we are using it.Jul 9, 2023Jul 9, 2023