Internals of Apache Iceberg
In this blog we are going to explore the architectural components of the Apache Iceberg.
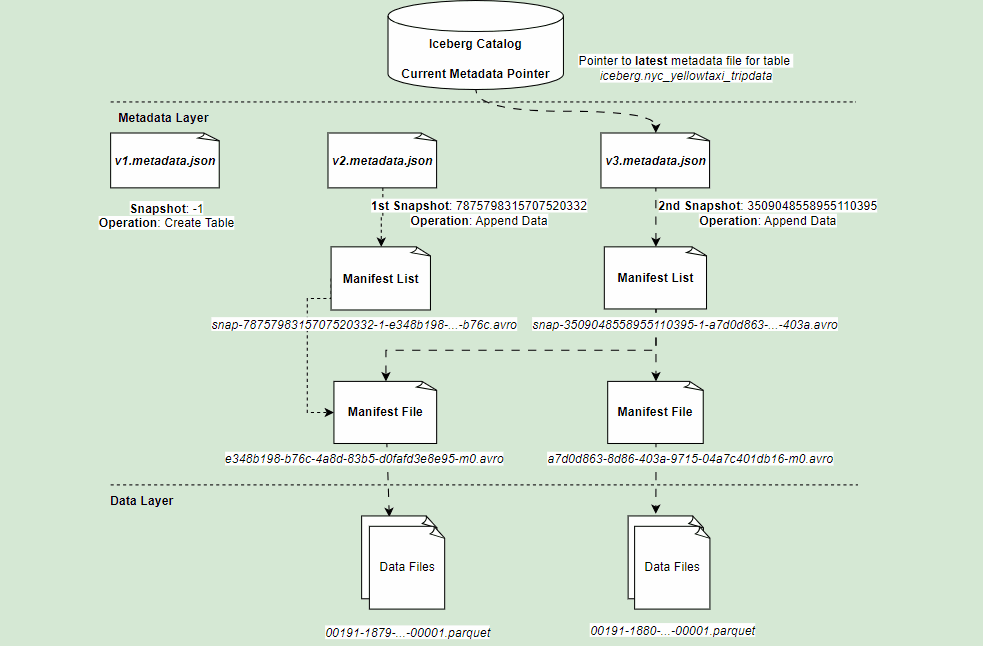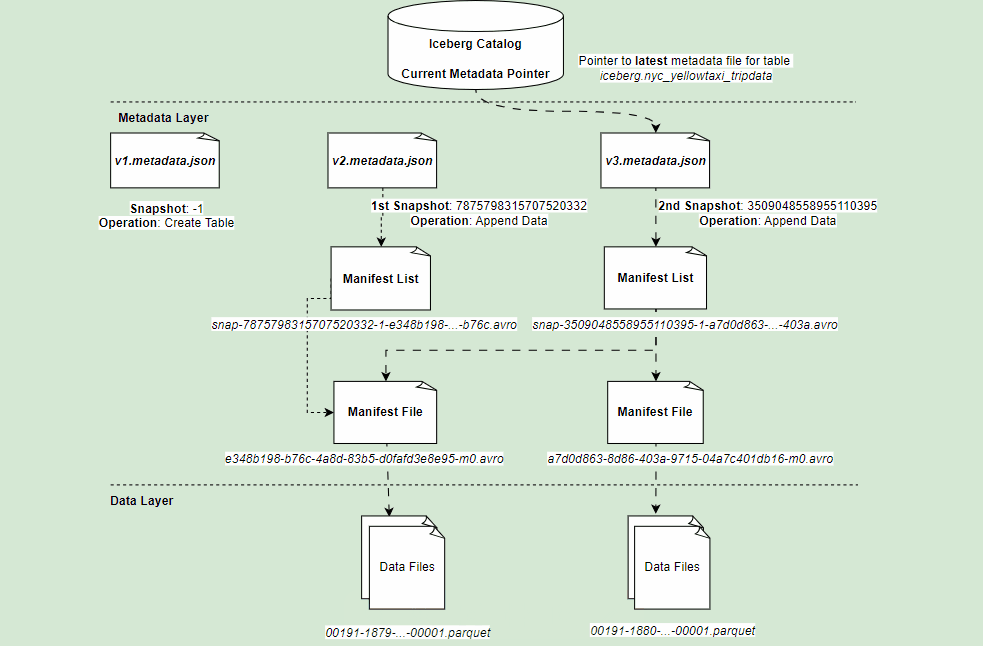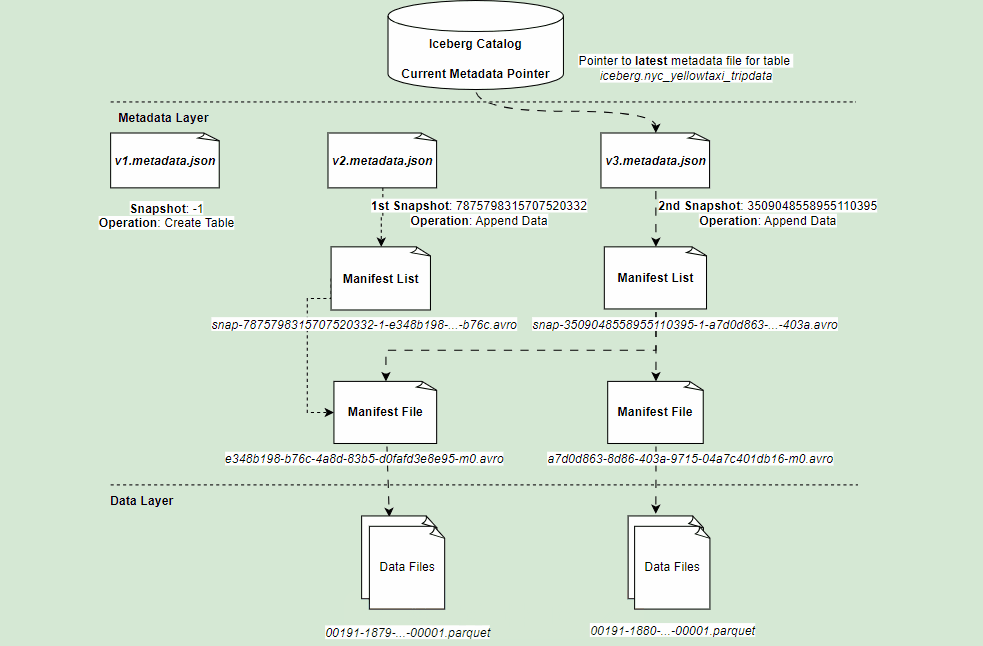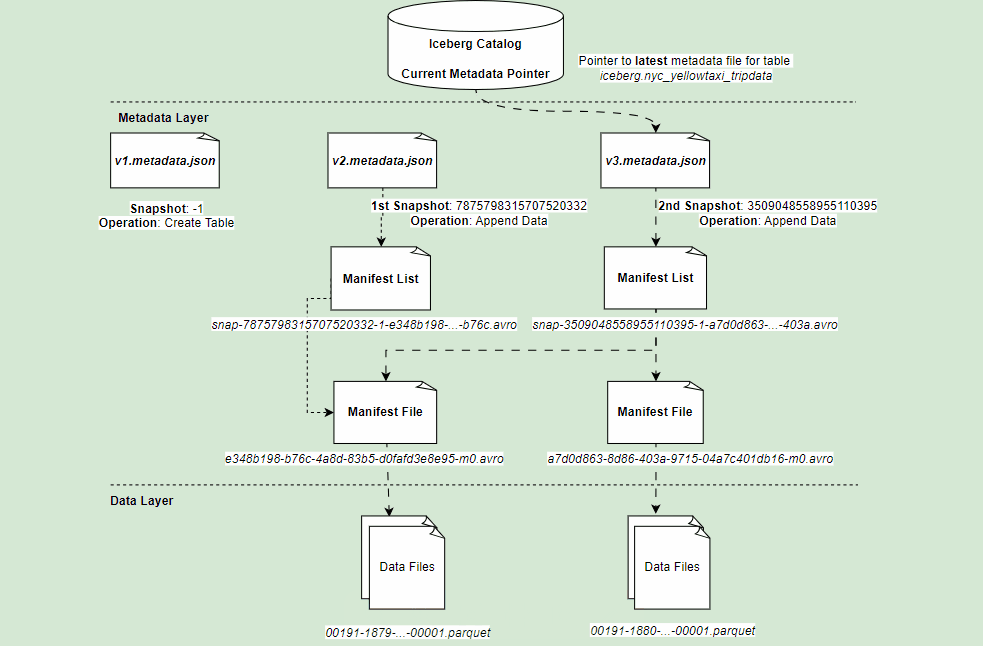
If you refer architectural diagram of an Iceberg table, it has three layer:
- Iceberg Catalog
- Metadata Layer
- Data Layer

Iceberg Catalog
- First point of contact for an reader/writer.
- Catalogs store the current metadata pointer for an Iceberg Table i.e. pointer for an table to its current metadata file.
- Primary requirement of an catalog is that it must support atomic operation for updating the metadata pointer.
- Iceberg support many catalog that can be used to track tables, like JDBC, Hive MetaStore (HMS), Glue etc.
- Catalogs are configured using properties under
spark.sql.catalog.(catalog_name)
Iceberg also supports a directory-based catalog in HDFS that can be configured using type=hadoop
Example: Creating spark session for directory based catalog.
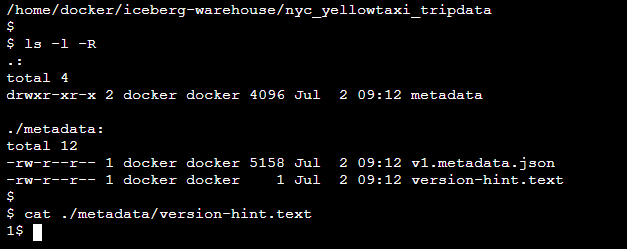
In case of HDFS as catalog, there is a file called version-hint.text in table’s metadata folder. Content of this file will tell you the version number for the current metadata file for that iceberg table.
I have created a Iceberg table using this directory-based catalog. It will create a table directory (data + metadata) in warehouse directory we have provided while creating spark session.
In below screenshot for iceberg table nyc_yellowtaxi_tripdata in metadata directory version-hint.text content is 1 i.e. current metadata file is v1.metadata.json
In case of details you can refer this iceberg documentation for catalog.
Metadata Layer
Middle layer of Iceberg table format which holds the metadata files.
Metadata File
Table state is maintained in metadata files. All changes to table state create an new metadata file & replace the old metadata file. It tracks :
- Table Schema
- Partitioning config
- Snapshots of table content
Let’s explore the content of first metadata file v1.metadata.json . This metadata file got created at the time of table creation.
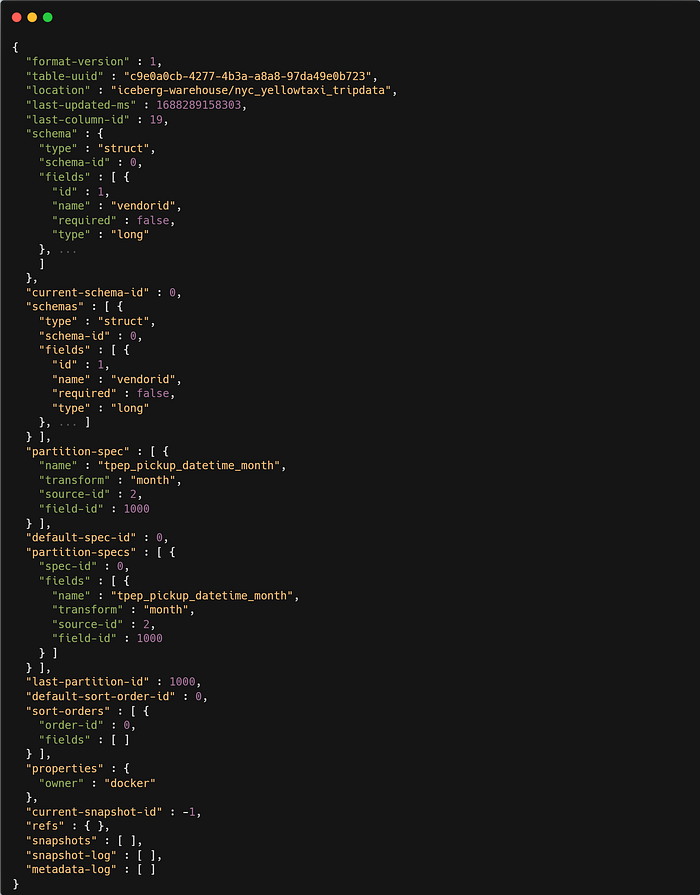
As of now we haven't ingested the data, that's the reason snapshot information is unavailable in metadata.json file.
Let’s append some data in table though Spark application.
As we have performed an operation, hence new metadata file (v2.metadata.json) is created.
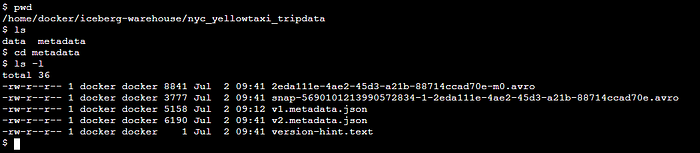
Now new metadata file is having all the information related to snapshot also:
- Current snapshot
- Summary of snapshot eg. operation performed, added files, added records etc.
- Location of Manifest List (one manifest file per snapshot)
- Tracking the metadata & snapshot log.
Excerpt from v2.metadata.json

Manifest List
- Manifest List is a group of manifest files that makes up a Iceberg table at that point of time.
- An Individual snapshot of the table can be made up of one or more manifest file. All these are listed in a Manifest List.
- One Manifest file per snapshot.
Content of Manifest List: It will give you snapshot details, location of manifest file, details of partitions eg. lower/upper bounds, row counts.
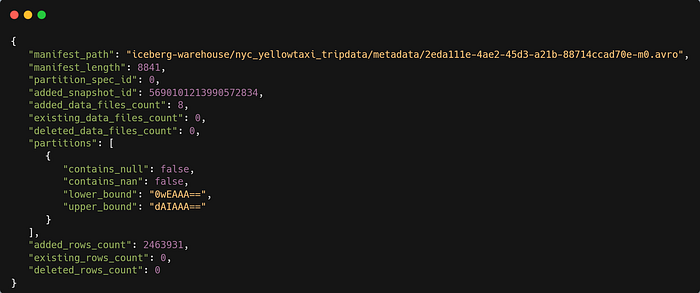
Manifest files are reused across snapshots to avoid rewriting metadata that is slow-changing. Manifests can track data files with any subset of a table and are not associated with partitions.
Manifest Files
List of data files along with all details (snapshot id, location of actual data file, file format, partition details, record_count etc.) & statistics about each data file (null, nan counts, lower, upper bounds).
Data files in snapshots are tracked by one or more manifest files that contain a row for each data file in the table, the file’s partition data, and its metrics. The data in a snapshot is the union of all files in its manifests.

Data Layer
The last layer of Iceberg table format, which actually hold the data files. Depending upon the file format (Parquet, ORC) defined for the table, this layer store the data files.
Representation of all layers & files: